Building TaleLens the AI-Native Way

Building TaleLens the AI-Native Way
Over the last year, the biggest change in AI products has not been the number of chat boxes on a page. It is that more products now assume AI should do more than answer questions. It should understand a goal, plan work, call tools, execute steps, and accept verification.
That is what AI-native means to me.
It does not mean "this product uses a model somewhere." It does not mean wrapping an existing workflow with a thin LLM layer. It means rebuilding the product, the engineering system, and the operating cadence around agents.
TaleLens naturally pulls us in that direction. We are not building a single-purpose feature. We are building a long creative chain that starts with user intent and runs through story understanding, planning, visual generation, character consistency, playback, export, sharing, and distribution.
AI-native means something different in 2026
Back in 2024, the question was whether AI was useful at all. By 2025 and now March 14, 2026, the more interesting question is whether products and teams have actually learned how to work with agents.
A few milestones make that shift obvious:
- On March 11, 2025, OpenAI introduced the Responses API and Agents SDK, turning web search, file search, computer use, and tracing into agent infrastructure.
- On July 17, 2025, OpenAI introduced ChatGPT agent and made research-plus-execution feel more like a product surface than a demo.
- On September 25, 2025, GitHub announced Copilot coding agent general availability, pushing coding agents into everyday software work.
- On October 6, 2025, OpenAI introduced AgentKit, packaging workflows, connectors, chat UI, and evals into a more complete agent stack.
- In December 2025, OpenAI, Anthropic, and Block helped launch the Agentic AI Foundation under the Linux Foundation, pushing standards such as
AGENTS.mdandMCPfurther into the open ecosystem.
So the real question is no longer whether you can plug AI into a product. It is whether your product and your team are actually organized around agentic work.
What AI-native means for us
1. The product is an AI system, not an AI feature
TaleLens was never meant to be "a thing that generates content."
What users actually want is closer to this:
- I have a fuzzy idea. Can you help me turn it into a strong story?
- I have a draft. Can you turn it into a consistent, multi-page illustrated piece?
- I have characters and a world. Can they stay coherent across pages and future books?
- Once the work is done, can I play it, share it, teach with it, and publish it?
That means the product cannot stop at a single answer. It has to move work forward: understand intent, break the task down, call different AI services, inspect the result, retry when needed, and return something usable.
In that sense, TaleLens is less "an app with AI" and more like an operating system for story creation.
TaleLens is already an agent pipeline wrapped in product workflow
If you only look at a slogan, TaleLens can sound like "an AI picture-book generator." But once you lay out the product flow, it is much closer to an agent pipeline wrapped in the right workflow guardrails.
At the entry point, TaleLens is not a toy prompt box. In New Tale, the user provides story text and configures page count, aspect ratio, style, and model. What the system receives is not a static parameter table. It is a creative objective: turn this idea into a readable, editable, multi-page work.
Then comes Plan, which is one of the most important checkpoints in the entire system. Plan is where user intent becomes an executable structure. The system interprets the story, organizes it into pages, and prepares the work before generation starts in earnest. This is a good example of the workflow-agent balance: the agent keeps its ability to interpret structure, but the user still gets a visible checkpoint where they can confirm, revise, or take over.
Workspace is where TaleLens becomes more than a one-shot generator. It already supports:
- editing the title, page titles, and body text directly
- regenerating a single page with custom prompts and model switching
- reviewing candidates, rejecting them, and restoring from history
- retouch-style image editing through conversational instructions
- iterating on the same tale instead of starting from zero every time
That changes the feel of the product completely. The core experience is not "AI made this for you." It is "AI is working with you to finish this book."
Asset Library is another deeply AI-native feature. It solves one of the hardest problems in any agentic creative system: long-term consistency. The library already supports private and public assets, uploads, parsing previews, prompt generation, retouch, version history, and saving assets from reference images or generated pages. Those assets can then be reused as characters, props, scenes, or reference-only constraints inside new tales, planning, and editing.
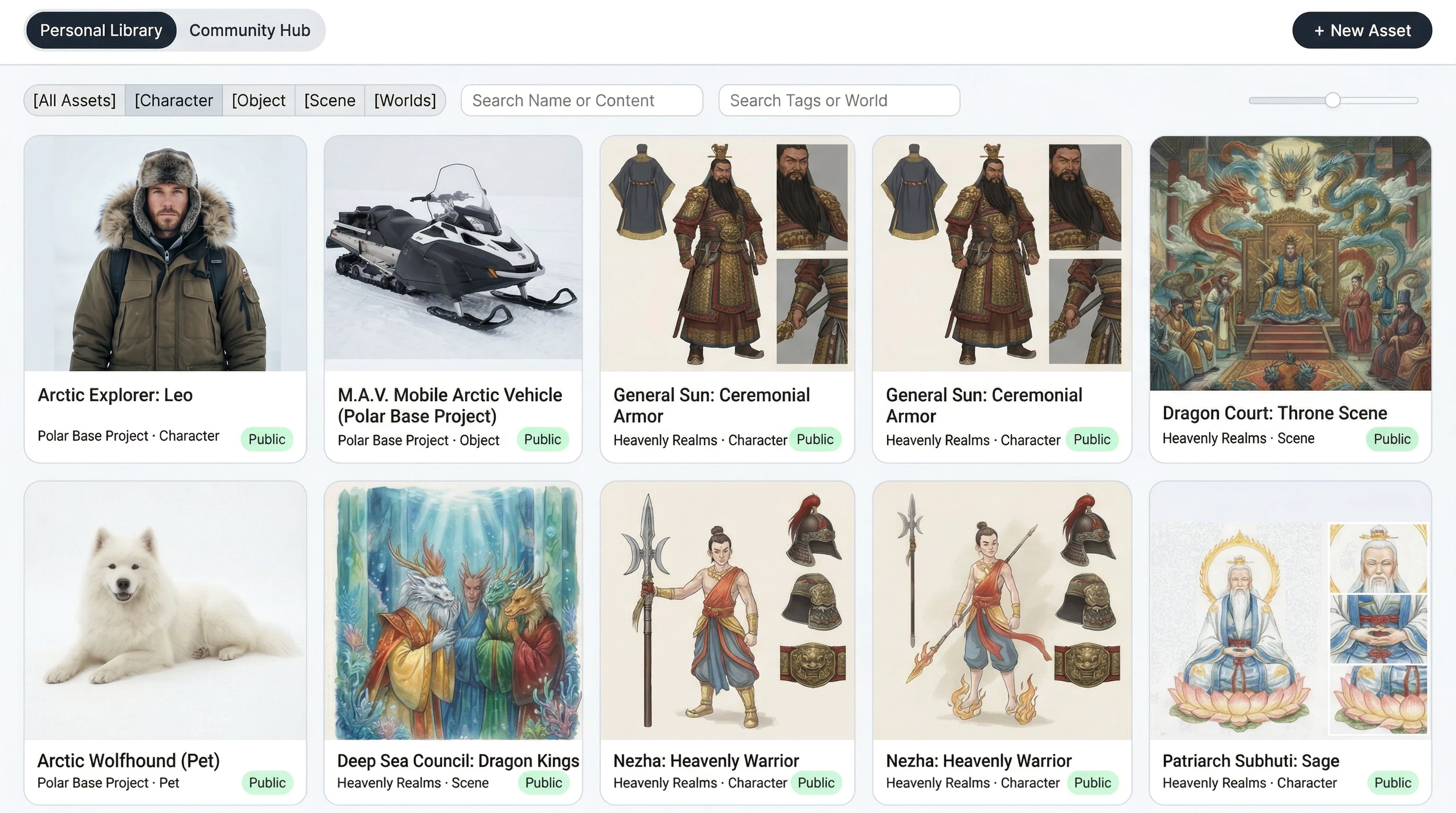
Grounded on the current TaleLens Asset Library UI.
That matters because it shifts TaleLens away from "re-understand the user from scratch every time" and toward persistent world memory. For agents, that is the difference between one-off execution and reusable creative infrastructure.
The output layer is just as important. TaleLens does not stop at editing:
BookViewerandPlaybackPagesupport reading and TTS playback- share pages and static links make stories publicly accessible
PPTXexport turns a story into something usable offline or in classroomsTale Galaxyand other spaces move a single tale into recommendation, community, and distribution surfaces

Grounded on current TaleLens library and public sharing UI.
Once a product spans generation, reading, sharing, and ongoing distribution, it is no longer a creative toy. It becomes a content system.
There is one more layer here that matters: Cloud Task. TaleLens is increasingly explicit about background jobs such as New Tale, Auto Fill, and Export Video, with visible status, notifications, and return paths. That is a very AI-native product stance. You are not calling a synchronous function. You are interacting with a system that keeps working after the click.
2. The way we build is AI-native too
An AI-native product becomes awkward if the development process stays entirely pre-AI.
We increasingly use AI across design, coding, debugging, testing, validation, documentation, and CI/CD. Drafting a PR, reviewing a change, filling a test gap, checking for regressions, or comparing implementation against requirements all have a lot of repetitive structure. That is where coding agents and automation are genuinely useful.
This does not remove the need for engineers. It changes what engineers spend their time on:
- designing system boundaries
- writing clear rules and context
- reviewing consequential decisions
- building evals, rollback paths, and safety constraints
An AI-native team is not a team with no humans. It is a team where humans spend less time on repetitive execution and more time on direction, quality, and constraints.
3. Operations should be agentic too
This part gets less attention, but it matters just as much.
We already use OpenClaw in day-to-day work for PR handling, code review, and blog management. We expect it to take on more system testing and community operations over time as well. Those tasks may not look glamorous, but they are exactly the kinds of activities that decide whether a product keeps running well.
We do not have dedicated full-time QA on the team. That does not mean testing matters less. It means testing has to become more systematic. An AI-native team cannot rely on "everyone being extra careful" before release. Regression checks, acceptance criteria, critical path tests, and release gates need to be made legible to agents so they can be executed and verified continuously.
OpenClaw is becoming the operations layer of the team
The internal ops docs in this repo already show something concrete. PR auto-merge is not a vague "AI helps productivity" story. It is a real chain:
GitHub Webhook -> webhook server -> OpenClaw agent -> pr-auto-merge skill -> Claude Code /pr:merge
That matters because it shows where OpenClaw sits. It is not just offering suggestions. It is starting to absorb parts of the engineering operations layer.
That layer is full of work that is structured but scattered:
- gathering PR and issue context
- checking changes against repo rules and historical constraints
- separating style issues from behavioral regressions
- deciding which tests matter for this change instead of running everything blindly
- turning noisy execution output into conclusions an engineer can act on
That is very close to the sweet spot of coding agents.
In TaleLens, the value is even clearer because the product surface is not one page. It is a chain across frontend, backend functions, storage, sharing, playback, billing, and community spaces. Many regressions do not show up as compile failures. They show up as:
- Plan failing to enter Workspace
- single-page regeneration breaking version history
PPTXexport silently failing- public share pages rendering incorrectly
- Galaxy publishing, ordering, or moderation drifting after a change
Those are exactly the kinds of failure modes where agents are useful.
The repo already contains a fairly serious P0 Playwright runner. It does not just click a few buttons. It covers the main user spine:
- login and session continuity
New Tale -> Plan -> Workspace- waiting for completion and verifying
Share / PPTXavailability - editing title and first-page content with E2E markers
- reopening a completed tale from history
- exporting
PPTX - generating a share link, previewing the public page, and then unsharing for cleanup

Grounded on TaleLens Workspace and public sharing UI.
That is valuable because it means the team has already written down the product lifeline as structured cases. The next logical step is to let OpenClaw do more than read them. It should execute them, observe them, summarize them, and track them over time.
If we push that idea further, the ideal testing role for OpenClaw looks something like this:
- select the most relevant regression set based on the current diff
- boot the right local or staging environment with test accounts and fixtures
- run critical-path scripts such as
test-ui/P0/run-p0.js - collect logs, screenshots, JSON output, and HTML reports
- classify failures in engineering terms like "share page regression," "playback manifest issue," "cloud task status drift," or "Galaxy publish flow broken"
- decide whether to auto-fix, escalate for human review, or block the merge
That is much closer to what I mean by AI-native testing. The value is not that AI wrote a few test cases. The value is that testing itself becomes a persistent agent system with memory, accountability, and accumulation.
And no, this is not in conflict with not having dedicated QA. If anything, teams without dedicated QA should invest more seriously in agentic testing. Otherwise, release verification eventually collapses into "we looked at it and it seemed fine," which is not an engineering strategy.
So when we use OpenClaw for PRs, reviews, blog management, and later testing and community operations, those are not separate stories. They are the same story: long-running, discipline-heavy work should gradually move from human willpower to agent execution.
Why TaleLens is a natural fit for agentic behavior
TaleLens has a classic agent characteristic: users usually provide intent, not instructions.
Someone might say:
I want a warm bedtime story for my child about courage and friendship, and I would love to share it with family later with voice playback.
That sounds simple, but the real work behind it might include:
- inferring audience age and emotional target
- planning structure and pacing across pages
- generating or correcting character definitions
- choosing style and visual language
- preserving cross-page consistency
- generating narration or audio
- packaging the output for sharing, playback, or teaching
It is hard to freeze all of that into one rigid workflow, because creative work is not a fully closed problem.
That is why I think TaleLens is naturally agentic at the runtime level. We do not need a fancier form. We need a system that can understand intent, move the work forward, and still accept constraints and feedback at the right checkpoints.
Workflow versus agent is the wrong religion war
One of the most common mistakes in agent talk is the idea that more autonomy is always more advanced.
I do not buy that.
Anthropic made the distinction well in Building Effective AI Agents: workflows are strong when boundaries are clear and stability matters; agents are strong when the task is open-ended and step count is hard to predefine. That distinction is extremely useful in product design.
The model I find more convincing is this:
Workflows should provide strong patterns and structure. The operating process inside them should use AI.
In other words, the framework should preserve direction and reliability, while agents should exercise judgment inside that frame without being over-constrained.

In TaleLens, that balance is concrete:
- billing, permissions, publishing, safety, and export are better expressed as workflows
- story understanding, character evolution, style decisions, page polish, and content completion benefit from agent autonomy
- the system still needs checkpoints, visible state, and user takeover points between those layers
If everything becomes an agent, ordinary users are forced to become operators. If everything becomes a workflow, the product becomes rigid and good creative practice stops evolving.
The best AI-native products do not pick a side. They design the interface between the two.
Context engineering matters more than prompt engineering
Once you start building agents, one thing becomes obvious very quickly: quality is often determined less by how long your prompt is and more by what context reaches the model, when it arrives, and in what form.
Anthropic described context engineering as a natural extension of prompt engineering, and that framing feels right to me.
Agents rarely fail because they cannot produce text. They fail because:
- the context window is flooded with noise
- the context is too thin to support action
- the right context arrives too early or too late
This maps almost perfectly to the experience of working with coding agents.
A good coding agent is not one that sees the entire repo all the time. It is one that gets the right things at the right moment:
- project rules like
AGENTS.md - the files relevant to the current task
- the tests that matter
- the current branch state and verification output
- a goal that is clear without being overloaded
TaleLens needs the same kind of discipline. Not all information should stay resident all the time. Story briefs, character definitions, style references, page plans, user preferences, safety constraints, and output goals should be disclosed progressively to the right agent at the right stage.

That is why I increasingly think one of the core crafts of AI-native product work is not prompt writing. It is context management.
Who stores memory? Who retrieves it? Who summarizes it? Who hands off to the next agent? When do you compact context? When do you reset it? When do you require a human decision? Those are not minor optimizations. They shape the ceiling of the whole system.
AI-native is not about more automation. It is about more responsible automation.
I am not romantic about this.
I do believe agents will change software deeply, but there are real costs:
- latency and cost go up
- errors can cascade
- UI automation and tool use are fragile
- without evals, a system can look "good enough" while remaining unreliable
- if you surface too much complexity, users get exhausted
So no, I do not think "fully agentic" automatically means more advanced.
Most users do not want to become prompt engineers. They do not want to learn an orchestration language. They want a system that is smart without being reckless, proactive without being theatrical, and flexible without offloading responsibility onto them.
That requires more discipline from product teams, not less.
The kind of AI-native app we want TaleLens to become
The ideal version of TaleLens is not a fully automatic generator. It is a creative system that knows how to collaborate:
- users provide direction and judgment
- workflows provide stable structure and best practice
- agents interpret, plan, execute, and revise
- evals and testing prevent the system from becoming self-congratulatory
- operations agents absorb the long-running labor of PRs, reviews, blogs, testing, and community work
That sounds like product design, but it also sounds a bit like institution design.
An AI-native app is not just a UI. It is a system that keeps running. It knows when to create, when to converge, when to act on its own, and when to hand a decision back to a person.
If older software design was largely about arranging features neatly, AI-native design feels more like building a stage for agents to work on, while making sure the performance still has rhythm, boundaries, and quality.
That is what we want TaleLens to become.
FAQ
Is an AI-native product the same thing as an agentic product?
Not exactly. Agentic usually emphasizes planning and execution behavior. AI-native is broader. It means the product, the engineering process, and the operating model are all reorganized around AI.
Will TaleLens become fully agentic?
Not by ideology. We would rather make the high-uncertainty parts of creation more agentic and keep high-certainty areas such as safety, publishing, billing, and export more workflow-driven.
Is it risky not to have dedicated QA?
It is risky if that simply means "less testing." It is much less risky if it forces the team to build explicit regression suites, eval sets, acceptance gates, and automated validation as part of the system. That is exactly the role we want tools like OpenClaw to grow into.
References
These public materials informed this piece, with access current as of March 14, 2026:
- OpenAI, New tools for building agents
- OpenAI, Introducing ChatGPT agent: bridging research and action
- OpenAI, Introducing AgentKit
- OpenAI, OpenAI co-founds the Agentic AI Foundation under the Linux Foundation
- GitHub, Copilot coding agent is now generally available
- Anthropic, Building Effective AI Agents
- Anthropic, Effective context engineering for AI agents